ai绘画StableDiffusion学习记录(十)ControlNet

ai绘画StableDiffusion学习记录(十)ControlNet
ZHYControlNet可以对你想要调整的元素进行微调,比如人物姿势等。
预处理器可以从图片中提取特征信息,controlNet模型读取这些信息引导sd生成图像。
安装模型花了我不少时间,真正使用起来效果还是挺直观的
openpose
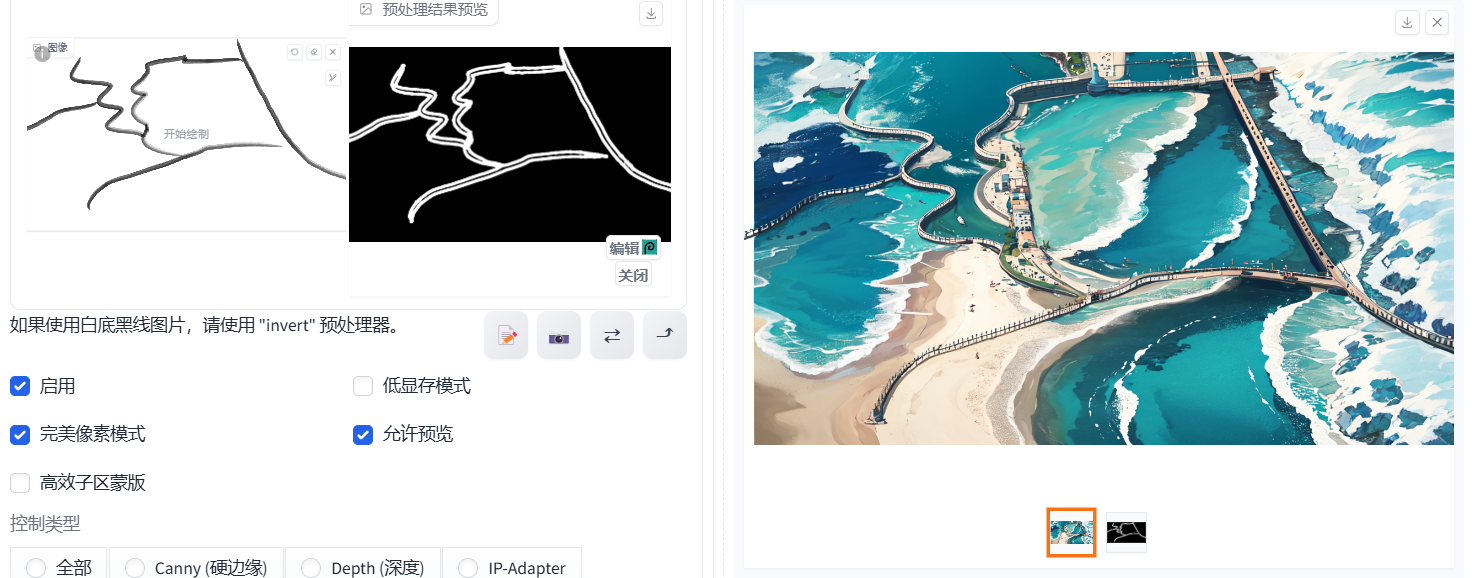
准备一张图片,让生成的图片跟你准备的图片里的人物姿势一样。有很多预处理器可以选择。如下图:
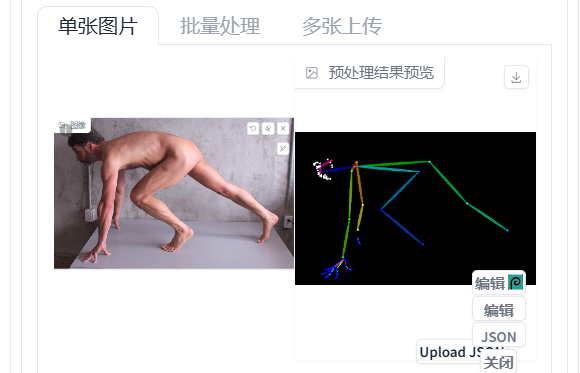
成图

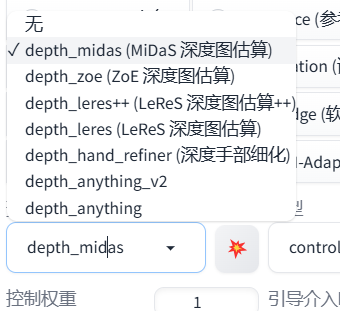
depth
深度

对于精度需求不高的场景,可以选择midas或者zoe预处理,比如生成人像。
有时候生成的图片跟样图不一样,比如下面这张图。
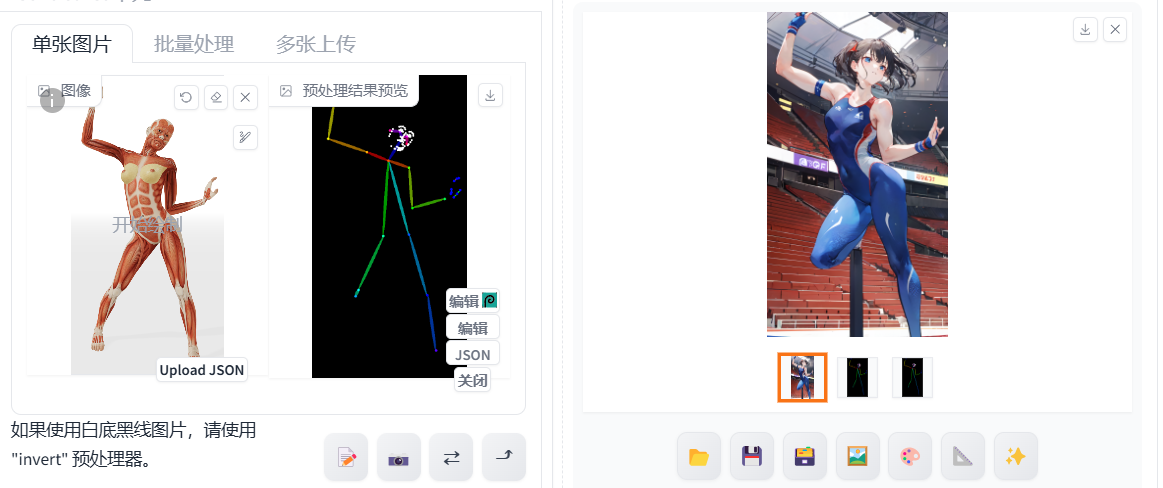
因为ai只知道在哪些位置要生成内容,不能分清手脚之类的。这时候可以使用depth,它生成的图片姿势会跟样图一样。相对应的生成图片更固定,创造力不如前面的openpose。
案例一
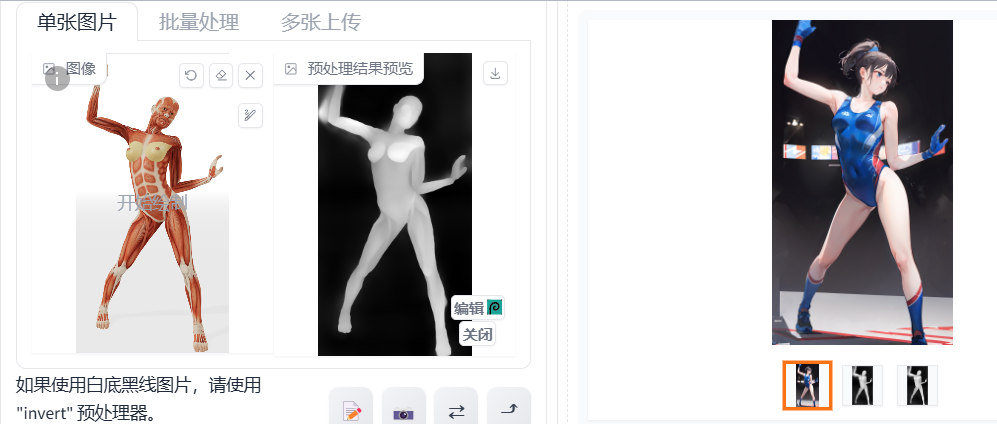
案例二


Canny(硬边缘)、Lineart(线稿)、SoftEdge(软边缘)
这三个都是根据线条来控制出图效果的算法。当然选择不同的预处理器或者不同的模型,出图效果也会不同,这需要自己去一个个尝试。
Canny主要将轮廓记录,ai根据轮廓出图。会有一些细节没法完美还原。比如例图里都没有右手。
Lineart会更细致,很多细节都能还原,几乎一比一复刻。很适合用来做照片动漫化等操作。
SoftEdge生图的自由度更高,线条边缘有羽化,更加模糊自然。(需要抽奖更多次)
原图

例图1:Canny

例图2:Lineart

例图3:SoftEdge

Scribble(涂鸦)
如果直接导入一张图,它可以提取动画线条,生成的结果有点像上面那些线条预处理的效果。
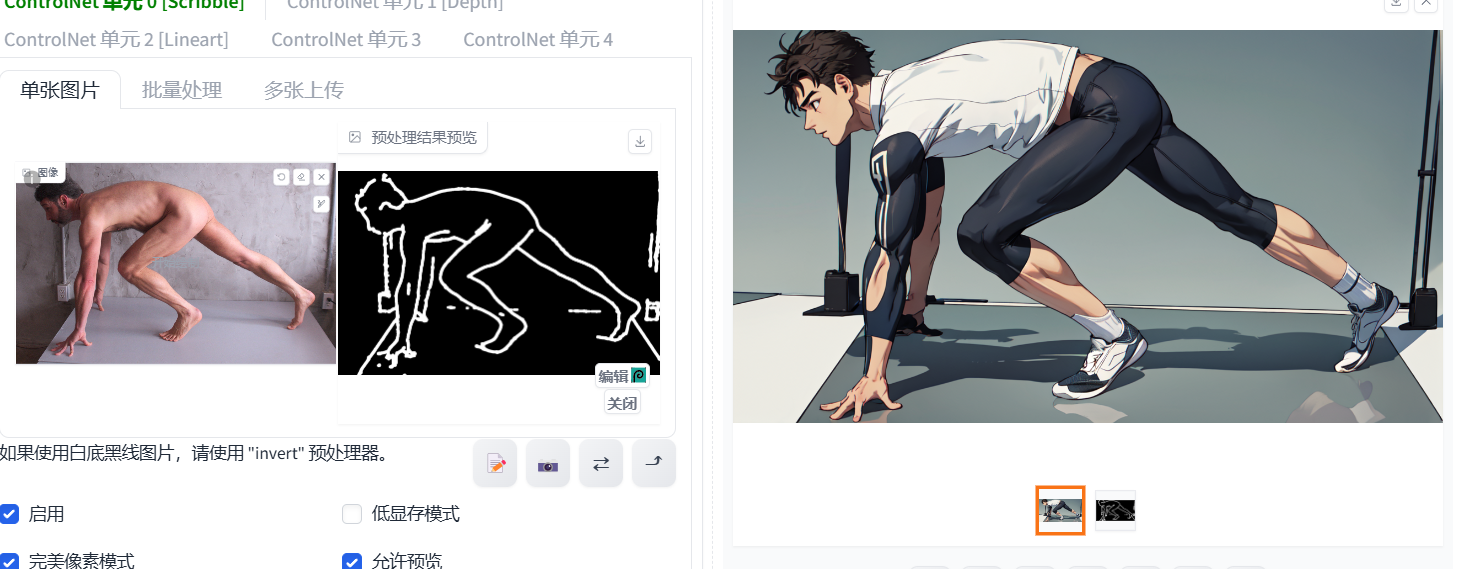
Scribble有点类似图生图,你还可以给一个随机乱涂的图片,ai通过关键词为你生成想要的内容,并且根据你涂画的结构线条等内容进行生成。
比如你可以完全更改提示词的内容,图像也不会崩。
Beautiful scenery,sunshine,beach,sea,don't have anyone, |